文章目錄

我們使用Google 的SLICE OF MACHINE LEARNING 平台來學習監督式學習中的決策樹方法。在此互動式的活動中我們將瞭解如何使用決策樹建構機器學習分類模型,並將食物分類為披薩或不是披薩。
- 活動目的:利用決策樹方法教電腦辨識披薩
- 活動項目:機器學習應用
- 活動平台:Slice of Machine Learning
- 使用環境:桌機或手機
Step 1 設定目標:
活動一開始,你需要先設定希望模型準確度(Accuracy) 的目標( 如下圖)。在機器學習中,準確度是分類模型預測正確的部分。你可以使用預設的準確度 80%。

你也可以自行調整想要的準確度目標。本活動將設定希望披薩分類模型可以有 85% 的準確度。

Step 2 拆分資料:
資料通常分為訓練資料和測試資料,主要是因為這種方法允許我們訓練機器時,可以用它還沒有看到的資料驗證它的準確性。此網站預先已收集好各種食物照片來做為訓練資料和測試資料。
系統在活動開始時,預設會將資料拆分成 80% 的訓練資料和 20% 的測試資料。訓練資料若太少,模型就沒有足夠的資料可學習;相反的,測試資料太少則無法測試出模型是否足夠好。

為了訓練分類器可以區分” 披薩” 和 ” 不是披薩 “,我們將向它提供各種食物的資料:披薩、沙拉、餅乾等等。分類器將在該資料中尋找唯一識別披薩的模式( 例如,” 大多數披薩都有奶酪 (cheese) “),並使用其發現來預測新食物。
其中每筆食物資料都包含了 ” 碳水化合物(CARBS) ” , ” 肉類(MEAT) ” , ” 起司(CHEESE) ” , ” 卡路里(CALORIES) ” , ” 原產地(ORIGIN) ” , ” 圓形(ROUND) ” , ” 紅醬(RED SAUCE) ” , 和 ” 方法(METHOD) ” 等8 種特徵,同時標示是否為披薩(IS PIZZA) 用來訓練模型。

Step 3 進行訓練:
利用 80% 的訓練資料,您已經訓練了一個決策樹模型可以對披薩進行分類( 如下圖)。每個藍色矩形代表食物的一個特徵(例如 ” 紅醬(REDSAUCE)” )。若要對食物進行預測,可從樹的頂部開始。對於您遇到的每個藍色矩形,如果它包含該特徵,則遵循” 是(YES) ” 的路徑,如果不包含此特徵,則遵循 ” 否(NO)” 的路徑。決策樹機器學習演算法非常聰明,它會自動確定樹分支的順序以獲得最佳準確度分數。
例如,選擇 ” 紅醬” 判斷是否為 PIZZA 的特徵?答案若 ” 是 ” 則往左走。製作方法是否用平底鍋煎?答案若 ” 是 ” 則往左走,即是 PIZZA,其他都會被篩選掉為不是 PIZZA。我們可以單擊菱形查看訓練資料的最終位置。

此時根據訓練資料進行訓練可以獲得 92% 的準確度。現在,讓我們在測試資料上執行這個模型,看看效果如何。

Step 4 預測評估:
使用 20% 的測試資料來評估這個決策樹模型,我們會得到下面這個答案。具有紅醬特徵但不是用平底鍋製作的本來會被分類為不是披薩,但可以清楚看到有部分披薩是被分到這邊 ( 下圖中的黑色點)。

下圖則是測試資料的準確度,距離目標85% 還有一段距離。其中您的訓練準確度很好 (92%),但測試準確度 (75%) 卻低得多,什麼地方出了錯?

這是一個常見的機器學習問題,稱為過度擬合(overfitting)。我們可以嘗試修改功能以達到或超過原設定的目標。例如調整訓練資料/ 測試資料的大小,或在決策樹中特徵的順序,以獲得更好的結果。
方法一:調整訓練資料/ 測試資料的大小

你可以左右移動中間的控制點來調整訓練資料與測試資料的比例,並看看調整效果。但要注意一件事就是如果測試資料過少,你將沒有足夠的測試資料可以知道模型有多好。
方法二:調整決策樹中特徵順序
調整過程中可以選擇 1~2 個特徵當作決策樹的分支節點,來進行模型的訓練。而模型的訓練結果將會受到所選取的特徵,以及先前所決定訓練資料集和測試資料集的大小比例而決定。當選完特徵,並且滿意此次的訓練準確度後,就可以接著下一步,測試模型預測的準確度了。
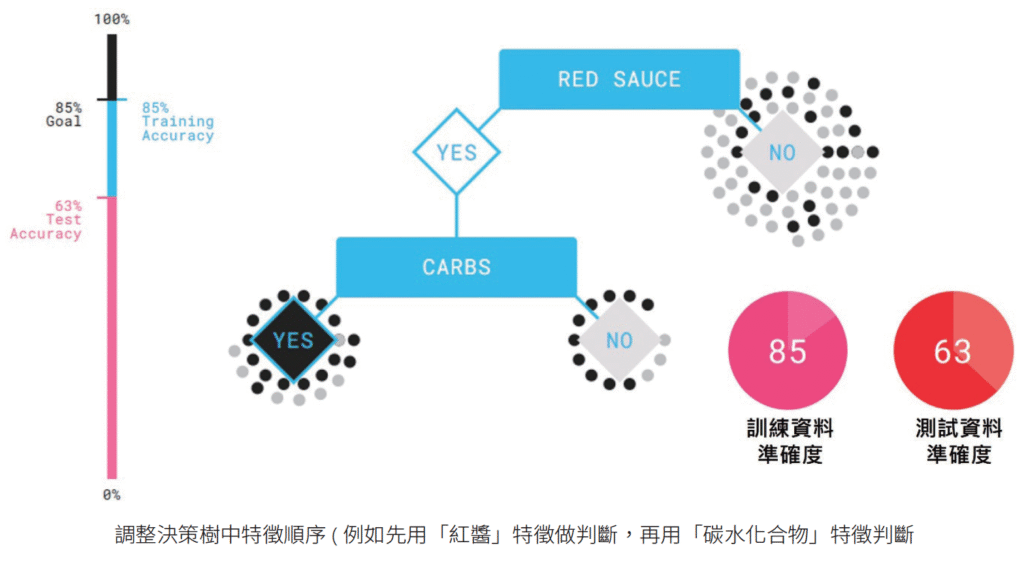
在訓練過程中,您會發現到訓練資料準確度高不代表最後測試資料準確度就會高( 如下圖的特徵順序)。

而測試準確度低的代表我們選擇的某些特徵對於判別披薩是沒有用的 (如下圖的特徵順序)。經過重複多次的訓練測試,可以看到紅醬 (RED SAUCE) 不管跟甚麼特徵搭配,測試準確度都較低,所以紅醬 (RED SAUCE) 對於判別披薩的幫助不大。
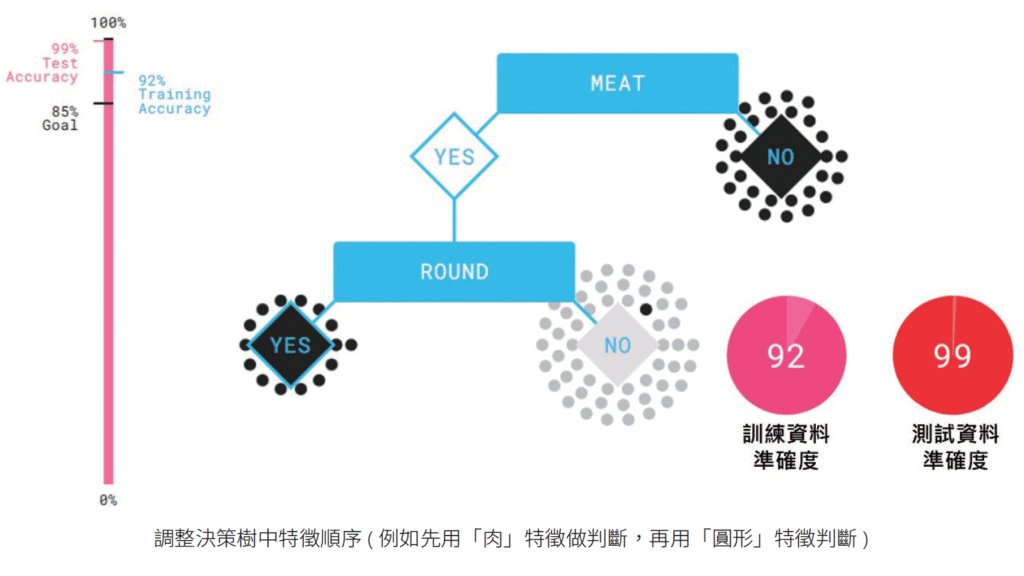
且越接近根節點的節點選擇的特徵會影響越大,靠近根節點的節點選擇的特徵會比後面的節點更早將資料篩選完,越前面的節點若選對特徵,就能大大提升判斷效率( 如下圖)。
這個活動的優點是在 No Math No Code 的情況下,把機器學習中的決策樹演算法變的簡單易懂,操作上也很容易,同時可理解在監督式學習類型上的應用,對於剛接觸機器學習的人非常適合。
如果大家想要多了解一些 AI 或 生成式 AI 的基礎概念,可以參考這一本書《 「生成式⇄AI」:52 個零程式互動體驗,打造新世代人工智慧素養 》,或是 SimpleLearn|Online 課程,它將帶領讀者在不會程式、不會數學也OK!的情況下,了解整個 AI 到 生成式 AI 的相關觀念及應用,不僅可以建立最完整的 AI 入門知識,更是培養 AI 素養的最好學習內容。
如果你喜歡這篇文章歡迎訂閱、分享(請載名出處)與追蹤,並持續關注最新文章。同時 FB 及 IG 也會不定期提供國內外教育與科技新知。