文章目錄
本篇文章將帶領讀者進入由 Google 建立的 TensorFlow Playground,並且教大家實作兩個簡單的專案。實作之前,先帶大家認識平台的幾個特色:
- 平台具有高度視覺化,可幫助初學者了解神經網路
- 不需要數學及編寫程式就可以了解神經網路的最佳應用
- 使用瀏覽器,就可以輕鬆建立一個神經網路並且立即查看結果
- 激勵函數 (Activation Function) 可參考另外一篇貼文介紹
TensorFlow Playground 是一個 瀏覽器中的互動式神經網路視覺化工具,讓使用者可以在不需要寫程式的情況下,觀察神經網路的學習過程。現在就讓我們進入平台開始探索神經網路的奧妙之處。
- 活動目的:本活動旨在透過互動式操作與視覺化呈現,讓參與者能夠以直觀、易懂的方式理解神經網路的運作原理與學習過程。藉由操作 TensorFlow Playground 平台,參與者不需撰寫程式碼,即可:
- 親手調整神經網路結構與參數,觀察模型如何進行學習與分類。
- 透過視覺化畫面即時理解權重變化與誤差收斂過程,強化對深度學習概念的認知。
- 建立人工智慧基本素養,培養對 AI 模型建構與調整的初步理解與興趣。
- 鼓勵探索式與實驗式學習方式,提升問題解決與邏輯推理能力。
- 活動平台:A Neural Network Playground
- 使用環境:桌機或手機
Step 1 環境介紹:
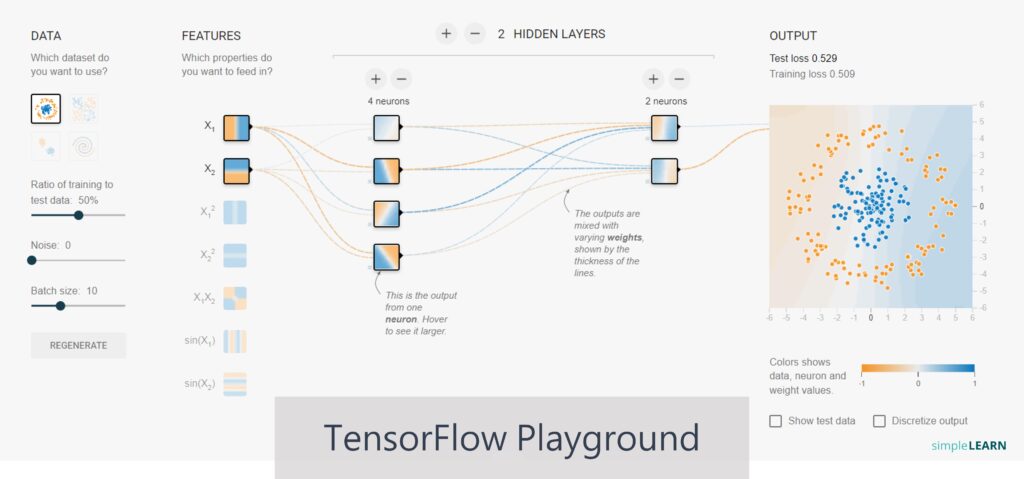
在帶大家實際操作前,我們先介紹一下此學習平台的介面操作( 如下圖),大家可以先到 Google 的活動平台 A Neural Network Playground。

1. 選單:

- Epoch (時期):對整個資料集進行完整的訓練。當進行訓練時,Epoch 數都會增加。
- Learning rate (學習率):學習率決定學習速度,同時會根據需求選擇合適的學習率。
- Activation (激勵函數):利用神經網路訓練時,需要選擇激勵函數類型,有關激勵函數的更多資訊可參考上一小節介紹。
- Regularization (正規化):正規化主要是用於防止過度擬合 (Overfitting) (可參考3.3.1 監督式學習),TensorFlow Playground 提供 L1 及L2 這兩種目前最流行的正規化方法,其中 L1 將分配較大的權重值給選擇的特徵,而未選擇的權重將變得非常小或者變成零,L2 則是減少特徵權重的差異,讓某些特徵的權重不要太突出,另外dropout 也是一種正規化方法。
- Regularization rate (正規化率):較高的正規化率將使權重的範圍更加有限
- Problem type (問題型態):兩種問題類型提供選擇,分別是分類 (Classification) 和回歸 (Regression)。
2. 資料集:

- Dataset (資料集):選擇不同的問題型態時,將會改變資料集的選項,其中分類問題資料集 (Classification dataset) 有四種,回歸問題資料集 (Regression dataset) 則有二種。

- Ratio of training to test data:可以控制訓練集與測試集間的百分比,也就是在資料集中要拿多少百分比的資料來進行訓練,其餘的當作測試資料用。 其中藍色和橘色點形成資料集,橘點 = -1,藍點 = +1。
- Noise (雜訊):可以控制資料集的雜訊水準,隨著雜訊的增加,資料模式變得更加不規則,調整雜訊後,可以在右邊看到資料集的分佈情況 。
- Batch size (批量大小):批量大小會決定每次訓練迭代使用的資料量。
3. 輸入層:

- Features (特徵):TensorFlow Playground提供7種特徵選擇,以前面兩種為例,x1 是水平軸上的值,x2 則是垂直軸上的值。
4. 隱藏層:

- Hidden Layers (隱藏層):隱藏層結構,TensorFlow Playground最多允許使用者設置 6 個隱藏層,以及每個隱藏層最多可設置 8 個神經元。當然,真正在寫神經網路或深度學習的程式時,是不受這些限制。
5. 輸出層:

- Output (輸出層):最右邊是輸出結果的顯示,可以看到損失值的變化情況,包括測試損失(黑色)和訓練損失(灰色),都將顯示在性能曲線中,如果損失減少,曲線將下降。
如果相關參數或環境都設定好後,按下左上角的 就可以開始體驗神經網路的訓練。接下來我們將帶大家實際操作兩個專案,讀者將可會更了解神經網路的運作方式。
Step 3 專案一:使用 1 個神經元進行分群 (clusters) 分類

- 專案目標:將兩個分群(clusters) 的資料進行分類
- 專案設定:
- 參數設定:
- Learning rate : 0.03
- Activation : ReLU
- Regularization : None (解決簡單問題時可以不需要正規化,因為過擬合情形比較不會發生)
- Regularization rate : 0
- Problem type : Classification
- Ratio of training to test data : 50%
- Noise : 0 (為方便找到解決方案,可以將噪聲先設置為零,未來可以嘗試以更高的噪聲水準來進行更多練習)
- Batch size : 10
- Data:Gaussian
- Features:x1,x2
- Hidden Layer:一個隱藏層,並且只有一個神經元
- 參數設定:
設定好環境後( 如下圖),就可以按下 Run 鈕進行訓練。你將可以看到整個神經網路的訓練過程。

訓練完成後圖形及輸出的一些資料將如下圖。訓練之前,初始化測試損失 (Test Loss) 和訓練損失(Training Loss) 的值會不同,因為初始權重值是隨機設置,經過一層隱藏層及一個神經元的架構訓練後,測試損失和訓練損失值會變得非常小也非常快,並且它們的損失曲線將會重疊。因為這是一個簡單的問題範例,所以它會很快就執行完並且非常成功。

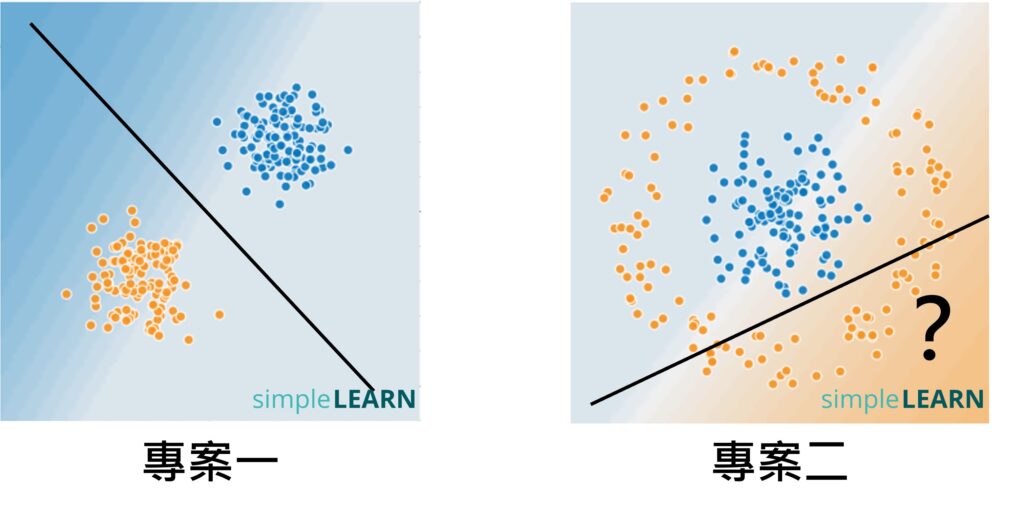
在訓練之前,神經網路無法區分橘色和藍色資料點之間 (如下圖左側),經過訓練後,橘色和藍色區域完美被區分開來 (如下圖右側),而中間那條分界線就是經過訓練後的模型。是不是跟 4.1 節所提的圖形很像。

Step 4 專案二:使用多個神經元進行分群 (clusters) 分類

- 專案目標:區隔上圖中這兩個資料集 – 即橘色資料以圓形包圍藍色資料
- 專案設定:
- 參數設定:使用與專案一同樣的參數資料
- Data:Circle
- Features:x1,x2
- Hidden Layer:專案二的問題比專案一的問題複雜很多,如果只利用一條直線是無法解決這個問題(如下圖),所以隱藏層可能需要多個神經元。我們可以使用1~3 個神經元分別測試其效果
- 我們在只有一個隱藏層及一個神經元的情況下訓練,測試損失 (Test Loss) 0.419 和訓練損失(Training Loss) 0.406 的輸出結果,表明分類失敗。
- 當我們使用兩個神經元來訓練時,性能雖然提高,測試損失 (Test Loss) 0.221 和訓練損失(Training Loss) 0.201 的輸出結果,分類還是失敗。
- 當我們換成 3 個神經元來訓練時,性能提升更好,得到測試損失(Test Loss) 0.003 和訓練損失(Training Loss) 0.001 的輸出結果,分類成功。
- 因為神經網路就是要最小化測試損失及訓練損失。
- 相關資料如下。也許您的數字跟作者不同,那是正常的,因為每一次訓練時出來的值不盡相同,但經過訓練後大致上會很接近。

而下圖是分別使用不同神經元的分類結果,當使用 3 個神經元時,可以看到完成了我們的目標,也就是可以將橘點和藍點分類出來,而這個邊界也就是訓練出來的模型。

讀者可以想像一下這些資料若是寵物的特徵,那這個邊界就相當於是可區分貓狗的模型。而當中神經元越多,神經網路將可以處理多元資料所生成的複雜邊界,同時也可以處理更多元的任務。
透過互動式操作與視覺化工具,我們不僅親眼看見了神經網路的學習歷程,更親身體驗了人工智慧背後的核心概念。AI 不再遙不可及,而是每個人都能理解,甚至親手參與的學習旅程。我們期待這次活動,能幫助大家更清楚地認識神經網路與 AI,並啟發你對未來科技世界更多的想像與探索。
如果大家想要多了解一些 AI 或 生成式 AI 的基礎概念,可以參考這一本書《 「生成式⇄AI」:52 個零程式互動體驗,打造新世代人工智慧素養 》,或是 SimpleLearn|Online 課程,它將帶領讀者在不會程式、不會數學也OK!的情況下,了解整個 AI 到 生成式 AI 的相關觀念及應用,不僅可以建立最完整的 AI 入門知識,更是培養 AI 素養的最好學習內容。
如果你喜歡這篇文章歡迎訂閱、分享(請載名出處)與追蹤,並持續關注最新文章。同時 FB 及 IG 也會不定期提供國內外教育與科技新知。